Digital Redaction Fails & Best Practices: How to Keep Your Sensitive Information Safe
3 September 2020For data security, timing is everything.

A mistake, the wrong information, revealed to the wrong party at the wrong time, could lead to deal-jeopardizing delays or reduced valuation amid a financial transaction.
In other contexts, privacy breaches could trigger potential fines, litigation legal costs and reputational damage.
Therefore, when it comes to sharing your sensitive information, you want to ensure your team has the tools and knowledge to control the flow of data altogether. That includes the information inside of documents, as well as the physical files themselves.
Content removal, known more widely as redaction, is used to filter information out of documents before sharing. However, one can easily find examples of high-profile redaction failures where firms, not understanding the risks, perform redaction the wrong way, to leave themselves and their clients exposed.
This article discusses commonly used digital redaction techniques and tips for how you can apply best practices to protect your information, improve turnaround times and reduce costs when filtering information out of your documents.
Typical redaction methods
In the past, teams performed redaction with Sharpies, scissors or a grease pen on paper. Today, most redactors go digital to speed up processes. Here are some commonly used digital techniques and their implications regarding security, timelines, and costs
Print, manual markup and scan
Many adopt a midpoint between full digitization and old-fashioned methods; they still print out documents, mark them up by hand, and rescan the redacted copies. On top of wasting trees and paper, these methods are somewhat messy and involve many slow and costly steps, including repeat work, especially when one has to reveal parts of redacted content later. Proofreading via these methods is also demanding and very slow, as one scans hundreds of passages line by line for sensitive strings with only the human eye.
Improvised Solutions
Some teams use digital solutions, leveraging features like searchable/selectable text to automate proofreading for sensitive keywords and strings. But they outsource to a collection of third-party tools, including email for collaboration on redactions. Therefore, disorganized, with little in the way of centralization or consistency, these methods can precipitate confusion and delays. Documents may be left free-floating across heterogeneous systems and apps. And as a result, teams could lose track of a document’s latest version or email an improperly redacted file to the wrong address.
Masking Solutions
Teams may also leverage solutions they find online, favored because they're accessible and easy to use. But these web-based tools, designed primarily for document viewing and collaboration, typically lack features to edit the file directly to eradicate content in redacted areas.
Instead, what these tools will allow you to do is mask content via annotations, dark highlights, or images layered over top. Best practice would thus be to then convert your documents with masked content to static image formats after, thereby removing the selectable/searchable text but also eliminating hidden layers within the file by flattening everything into a bitmap.
But teams may not be aware that this second step is even necessary, let alone how to flatten documents properly! And then it will then not be hard for someone to extract masked information underneath, as evidenced in a long list of redaction failures published by the American Bar Association.
This list includes the trial of lobbyist and consultant, and former Trump campaign chair Paul Manafort, convicted of tax and bank fraud. Manafort's trial lawyers masked content within interactive PDF documents, only for journalists in January 2019, to access the incriminating content underneath, in cases, by merely selecting over masked areas and copy-pasting to Notepad.
Likewise, PDF documents released recently by the U.S. government as part of the Jeffrey Epstein investigation were also reported to be improperly redacted, enabling public access to sensitive content underneath, once again, by simply selecting and copy/pasting.
Redaction the right way
Teams will want to protect sensitive information in their documents but also preserve the advantages of an interactive file format, in terms of selectable/searchable text, for example, to speed up workflows for both redactors and downstream users consuming redacted content.
For this very reason, many choose PDF for redaction, as the format has interactive text, as well as annotations, thus, theoretically, supporting the entire redaction workflow. That includes the proof-reading and redaction markup stage in draft mode, user discussion and approval of their redactions, and final eradication of specific content from redacted areas in the underlying file.
PDFTron and SS&C Intralinks team up to solve common web-based redaction pains
However, few tools currently support robust PDF redaction over the web. And that’s why Intralinks teamed up with PDFTron, a leading provider of document technology solutions for software developers, to embed professional web-based redaction directly in Intralinks’ virtual data rooms (VDRs).
The partnership centralizes and streamlines redaction workflows to eliminate repeat work, errors, delays and other costs associated with typical redaction methods.
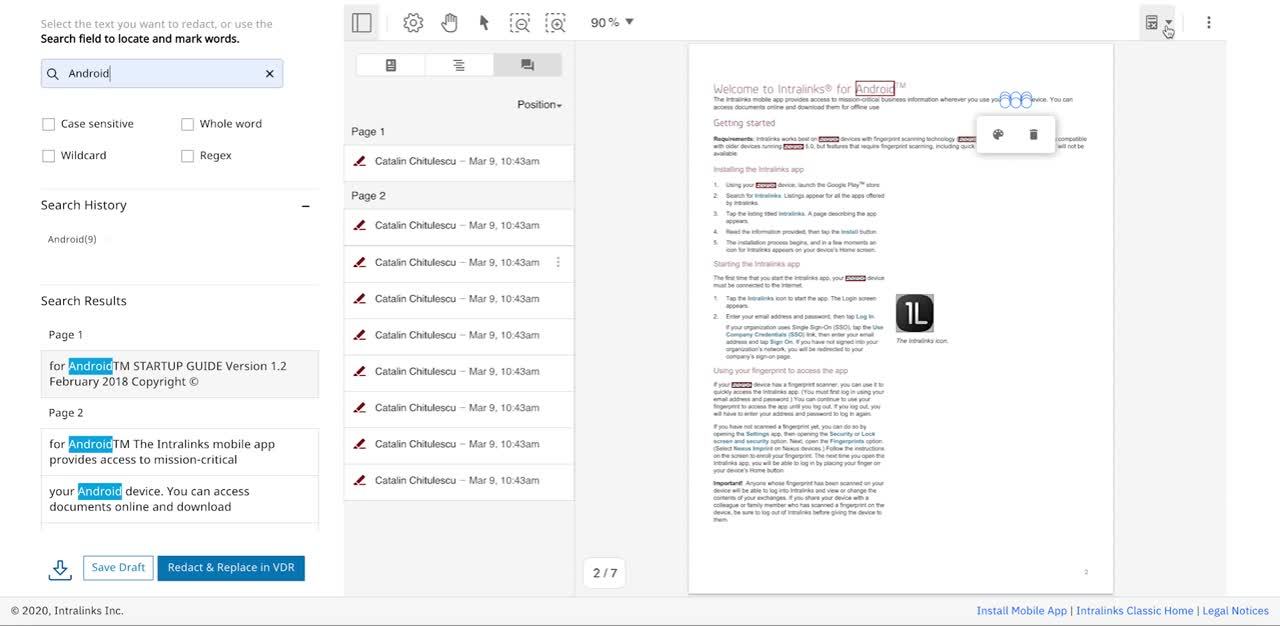
One issue we wanted to solve for teams was automating detection and elimination of sensitive keywords and strings, a common hurdle to getting their redactions done quickly.
However, even modern search technology can struggle with PDF due to the format’s complexity. One thing that surprises many is that the text in a PDF file is not stored as one would expect: according to its natural reading order, with characters grouped into words, words into sentences, sentences into paragraphs, etc. Instead, PDF uses a coordinate system for the placement of each character. Depending on how the PDF is generated, therefore, characters could be found in any order, even if a word occurs at the document's start. For example, the term ‘Hello’ would be broken into ‘H,’ ‘e,’ ‘ll,’ and ‘o,’ with each character found at a different location.
A search algorithm is thus challenged to reassemble PDF text in its natural reading order based on the relative location of characters. Extra white spaces or line breaks between words in a phrase are known to throw an algorithm off, unless it’s carefully calibrated to take account for these and many other edge cases. And where the search tool fails to detect a searched-for phrase, the user may miss it as well, even if the tool is 99 percent accurate.
(Above) To safeguard your deal and comply with burgeoning data security regulations, your information needs that extra layer of security that only redaction can provide.
Intralinks thus relies on PDFTron for its sophisticated PDF search algorithm to ensure users can rip through redactions on huge documents confidently.
On the other hand, the team at Intralinks worked to customize other PDFTron technology to make advanced search accessible to every user, for example, without any training.
One area of customization included PDFTron’s powerful regular expression searches. Unlike basic keyword searches, regular expressions use mathematical formulas to detect repeated patterns in a document such as phone numbers, social security numbers, addresses and so on. Instead of having to understand the math behind regex, users can now click the type of pattern they want to remove, like phone numbers, and Intralinks handles the rest.
The team at Intralinks also added instant unredact, so users can quickly reveal certain removed content later by reverting if it makes sense to do so, instead of redacting the entire document all over again.
The future of redaction
We’re going to continue to work together to refine the PDF redaction technology inside Intralinks, adding more features to make filtering information in documents faster and more secure.
In the interim, we can use your help. Have any redaction tips or fails of your own that you want to share? Don't hesitate to reach out to us with your stories and advice.

Adam Pez
Adam Pez is PDFTron's resident content writer and storyteller. He helps people in all aspects of document technology through expert industry advice, represented through practical, real-world examples. He also is a trained science communicator with two distinct master's degrees in Science and Technology Studies (STS) and Journalism.


